一、工作環境
在專題製作期間,教授給予我們充分的彈性與自主空間。製作環境不受限制,無論是在家中的書房、學校圖書館的自習區,或是咖啡廳等能夠專心投入的場所,都能成為我們的工作據點。這樣的彈性安排讓我們能依據個人習慣與當下需求,選擇最有效率的工作環境。
為確保專題進度穩定推進,我們平均每週與指導教授進行一次會議,在這些定期會談中,我們會向教授報告當週的專題進度、遇到的技術難題以及下階段的規劃方向。
教授也會針對我們的進度提供專業建議,協助我們釐清思路、突破瓶頸,並適時調整研究方向。這種定期且密集的指導模式,讓整個專題開發過程既具有彈性,又能維持明確的方向感。
二、專題詳述
1. 研究動機
學測放榜後,交叉查榜是學生與家長評估志願填寫的重要工具。然而,現有網站的資料分散於多個頁面,無法依科系、縣市或考區快速整合,也缺乏圖表化與視覺比較功能。使用者只能逐頁查詢,不但耗時,也難以掌握整體趨勢。因此,本專題希望透過爬蟲、資料庫與視覺化工具,建立一套能自動整合交叉查榜資料並提供互動分析的平台,協助使用者更有效率地進行查榜與資訊比較。

2. 資料來源
研究資料來源為交叉查榜網站,內容包含:
-
各縣市考區頁面
-
學校與試場連結
-
每位考生的申請校系
-
正取與備取順位(部分為圖片需 OCR 辨識)
-
錄取結果
3. 研究方法
(1)爬蟲技術
本研究使用 Python 實作自動化爬蟲,並採取多項技術以確保資料正確與穩定蒐集。
-
Selenium:用於操作動態網頁、處理網站反爬機制以及模擬使用者操作行為。
-
BeautifulSoup:解析 HTML 結構、提取表格內容、校系列表與個別考生資料。
-
OCR(Pytesseract):用於辨識網頁中以圖片呈現的數字,例如正取或備取順位、考生編號等無法直接擷取的資訊。
-
多層巢狀爬取架構:依網站階層設計爬取流程,包括:縣市 → 區域 → 試場 → 考生 → 校系 → 錄取與順位資訊
-
容錯與續爬機制:加入重試、等待、例外處理與頁面完整性判斷,避免因網頁延遲、資料漏抓或瀏覽器異常而導致爬蟲中斷。
透過上述方法,成功取得 113 年學測交叉查榜完整資料。
(2)資料庫建置
資料採用 SQL Server 進行儲存與管理,並根據分析需求設計五張主要資料表,以保持資料的結構化與關聯性。
-
欄位標準化:包括縣市名稱、校系格式、錄取狀態統一化。
-
主鍵與外鍵關聯設計:使不同資料表之間具有邏輯連結,便於後續查詢與視覺化。
-
資料清洗與整併:移除重複資料,並整合正備取順位、最終錄取情形及跨年份資料。
透過資料庫的整理,能確保 Power BI 在後續分析時具備一致且高品質的資料來源。
(3)資料分析與視覺化
使用 Power BI 作為分析與呈現工具,將大量資料轉換成可互動、易理解的視覺圖表,包含:
-
高中 → 科系 流向圖:顯示不同高中學生的申請與錄取流向。
-
正取與備取統計:展示各科系正備取人數與比例。
-
依地區、縣市、學校之互動式查詢:提供多條件動態篩選。
此外,本研究也使用 DAX 量值公式(Measures) 製作運算型指標,包括:
-
正取率、備取率
-
正取 / 備取 人數統計
-
依篩選條件動態計算的錄取人數
DAX 的運用使得報表不僅能顯示靜態資料,更能依使用者互動即時計算各項比例與指標,提高整體分析深度與實用性。
4.研究成果
(1)校系申請錄取指標
該模組用於分析各校系在申請入學階段的招生效率。它可以比較各校系在特定學年度的錄取率、報到率等關鍵指標,從而評估各校系對考生的吸引力及校系競爭強度,如下圖。

(2)校系隔年差額比較
此模組專門用於追蹤各校系招生名額的年度變化。它計算並視覺化「今年名額」相較於「去年名額」的差額,以協助使用者了解科系發展和招生規模的調整趨勢,如下圖。

(3)區域流失分析
分析各區域學生的正取/備取報到人數、人數比例情況,揭示學生地域流動特徵。它幫助學校了解在不同區域市場的競爭力與流失風險,如下圖。


(4)校系報到語流失統計
此模組提供�全面的報到和流失數據統計,包括正取和備取的報到率和放棄率,呈現學校整體招生表現與學生選擇傾向,如下圖。


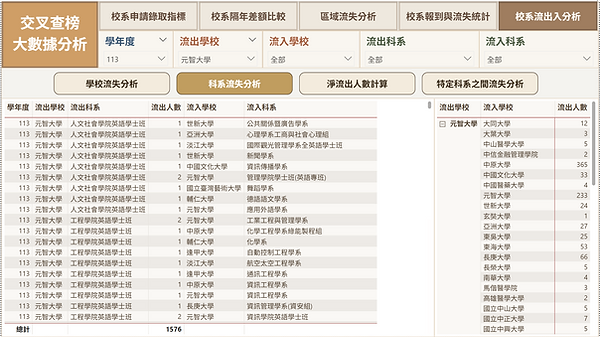
(5)校系流出入分析
這是最重要的分析模組之一,它追蹤學生在不同校系間的流動情況,呈現了學生流向和流失的具體路徑。它分為「學校流失分析」、「科系流失分析」和「特定科系之間流失分析」,幫助學校識別最主要的競爭者,如下圖。